 En
En
 Es
Es
A high availability cluster (HA cluster) is a group of servers that guarantees minimum downtime of virtual machines (VMs). High availability clusters are used, for example, to support database servers, for storage of important information, and for operation of business applications. If one of the cluster servers (nodes) loses connectivity with other nodes or the connected storage, VMmanager will start the process of VM relocation:
- move the VMs from the failed cluster node to the working nodes;
- shut down the VMs on the failed cluster node;
- isolate the failed cluster node.
Relocation is performed automatically without any administrator intervention.
High availability cluster requirements
You can create a high availability cluster under the following conditions:
- virtualization type — KVM;
- cluster network configuration — Switching;
-
storage types:
- for Hosting version — SAN;
-
for Infrastructure version — SAN and NAS in any combination;
No other types of storage should be connected to the high availability cluster.
- OS on cluster nodes — AlmaLinux 8;
- number of nodes — from 3 to 24 (maximum number of nodes the configuration has been tested with);
- system time on all nodes is synchronized. Use chrony software to synchronize the time;
- platform is not running on a VM inside one of platform clusters.
Recommendations
- It is not recommended to add problematic nodes to the cluster — servers that are tend to crash due to problems with OS, disks, network, etc.
- Before enabling high availability, make sure that network storage and its communication channels are working reliably.
- It is not recommended to set the RAM overselling ratio on nodes higher than 0.9.
- Set such a reserve of free resources that would allow you to place and start all VMs of the cluster selected for recovery in case of a single node failure.
- Use a high availability cluster for those VMs that are important to restore access to in the case of a disaster.
If the recommendations are not followed, there are possible risks:
- increased number of failures;
- lack of resources;
- software failures causing shutdown and redistribution of VMs in the cluster;
- failures in VM migration in case of node crash;
- loss of performance of some VMs in the cluster.
Operating logic
Services used
VMmanager uses the following to manage a high availability cluster:
The platform runs the ha-agent service on each cluster node. The ha-agent services communicate with each other using the Corosync software. Corosync algorithms assign one of the ha-agent services as the master. In the future, the platform interacts only with this service using hawatch.
Master selection procedure
Selection of the master takes place in the following situations:
- when high availability system is enabled in the cluster;
- when the current master goes out of service;
- when the HA cluster configuration is changed;
- when the HA cluster version is updated.
For the selection to be successful, it must involve (N/2 + 1) nodes, where N is the total number of nodes in the cluster. The value (N/2 + 1) should be rounded down to an integer. For example, in a cluster with two nodes, both nodes must participate, in a cluster with 17 nodes, 9 nodes are required. If there are fewer serviceable nodes in the cluster than necessary, the selection procedure will not start. If there are more nodes than necessary, only the nodes that were ready for the procedure earlier will participate in the selection. Corosync algorithms ensure that the information on the node readiness time is the same for all cluster members.
When selecting a master, each of the selecting nodes uses a special algorithm to calculate its priority and informs the rest of the cluster members about it. The node with the highest priority is assigned as the master. After assigning a master, the cluster will start in high availability mode.
Nodes that were not ready at the start of master selection are joined to the cluster after the selection procedure is complete. When new nodes are added to the high availability cluster, the master is not reselected.
Usually the selection procedure takes about 15 seconds.
Cluster node statuses
In a high availability cluster, ha-agent services can assume the following statuses:
- serviceable:
- Master node — the node is serviceable and has been selected as the master;
- Active — the node is serviceable and is a participant or in an intermediate running state (master selection or waiting for an update);
- non-serviceable:
- Network isolation — the node is not accessible via the network, but the node has access to the storage. The status is set if the node is unavailable to ha-agent services on other nodes in the cluster;
- No connection with storage — the node has no access to the storage, but remains accessible via the network;
- Unavailable — the node is unavailable via the network and has no access to the storage. The status is set if the platform does not have access to the node;
- Excluded from HA cluster — the node is unavailable via the network, but has access to the storage. The node's VMs are temporarily excluded from the cluster and are not migrated;
- special:
- Unknown status — the exact status of the node is unknown. For example, high availability is in the process of being enabled;
- Error enabling HA — the task of enabling HA on the node failed.
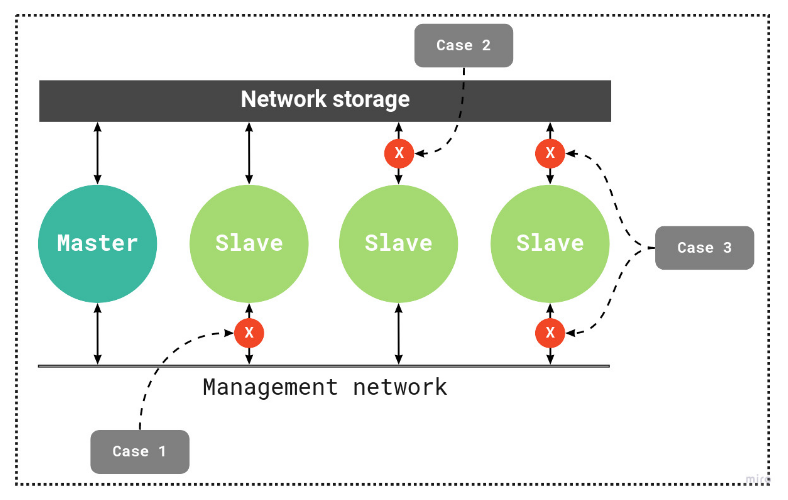
HA cluster operating scheme
Determining node status
The ha-agent service considers a node corrupted if it has lost connectivity with other nodes in the cluster and/or connected storage. Connectivity is verified using Corosync algorithms. Additionally, cluster nodes write information about their status to a file on the storage server. Status is updated once every three seconds. If the status information is not updated, the master will identify the node as damaged.
The average time to determine the non-serviceable status is from 15 to 60 seconds.
In high availability settings, a check IP address may be specified. If connection to the cluster is lost, the node will check the availability of that IP address using the ping utility:
- If the IP address is unavailable, the node will be isolated and the process of VM relocation will start;
- if the IP address is available, the node will be excluded from the high availability cluster. The VMs on this node will continue to work.
If a node regularly loses network connectivity for less than 15 seconds, it gets the status "network unstable". The relocation procedure is not performed in this case.
Disaster recovery procedure
When a cluster node is determined to be failed, the ha-agent service on the node:
- Shuts down all VMs. If the VM could not be shut down, the node will be rebooted.
- Isolates the node.
- Transmits information about the status of the node to the master.
When the master receives information about a node failure or independently identifies a node as failed, the VM relocation procedure is started. The order in which VMs are relocated depends on the startup priorities — the higher the priority value, the sooner they will be migrated. The relocation procedure is only started for those VMs, which were selected in the high availability settings.
After restarting the node, its VMs will start only if the node has one of the serviceable statuses — "master" or "participant". Only VMs that belong to this node according to the cluster metadata will be started. This approach avoids cases of "split brain", when two VMs are connected to the same disk at the same time.
Recovering VMs in a high availability cluster
In the high availability cluster settings, a list of VMs to be recovered is defined. The ha-agent services monitor and maintain the statuses of these VMs based on metadata received from the platform.
For example, a VM has the status "Active" in the platform settings. If a user shut down this VM using the guest operating system, the ha-agent service will restore its operation.
Deleting VMs in a high availability cluster
Before deleting a virtual machine, it is placed in maintenance mode. This prevents ha-agent services from performing actions on the VM while it is being removed.
Creating a high availability cluster
To create a high availability cluster:
- Configure the network storage. Read more in Pre-configuring SAN and NAS.
- Connect the storage to the cluster. Read more in Managing cluster storages.
- Configure the high availability settings. Read more in Configuring high availability.
Diagnostics
Сorosync configuration files:
- /etc/corosync/corosync.conf — general settings;
- /etc/corosync/storage.conf — storage settings.
ha-agent service log file — /var/log/ha-agent.log.
hawatch microservice log file — /var/log/hawatch.log.
Related topics:
Knowledge base articles: